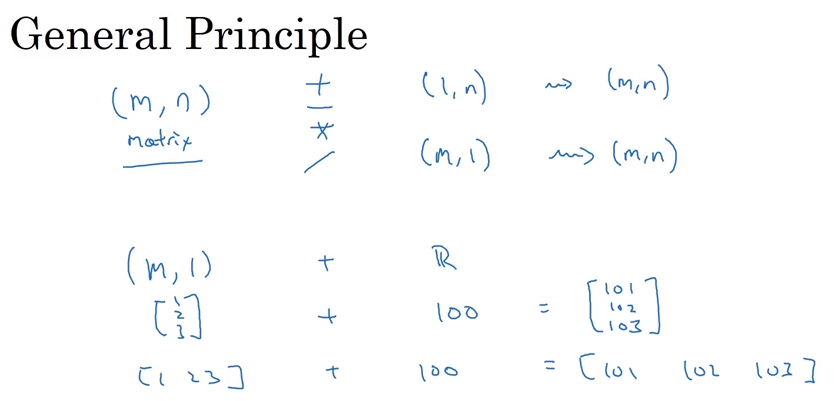第二周
- 二元分类(Binary Classification)
在计算机中存储彩色图片是分别存储红绿蓝三色矩阵,在进行表示的时候是把数值按照R、G、B的值纵向排列成一列。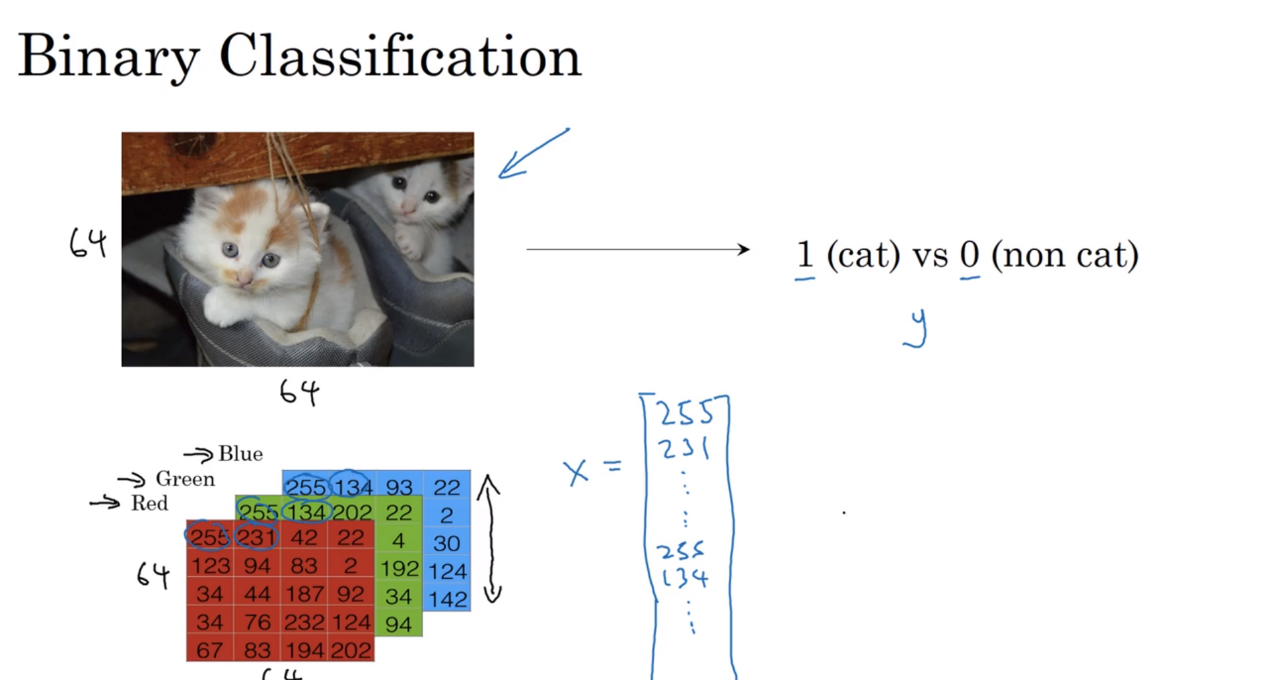
在上面的例子中,如果图像大小是64*64,则代表整个矩阵的大小是64*64*3,总共大小为12288,也就是说二元分类的目的就是输入一个以特征向量x所表示的图像,然后推测输出的y的值是0还是1。
在进行训练的时候,单个样本用(x,y)来表示,x代表一个n(x)维的特征向量,y代表了结果集0和1。所以训练样本就是x到y的一个结果。为此定义一个矩阵X,这个X是由训练集中的输入x(1)、x(2)…x(m)组成的,在X矩阵中这些输入都是按照列进行排列。
- 逻辑回归(logistic regression)
逻辑回归要处理的问题是因变量为分类变量的问题,因为线性模型主要处理连续变量问题,而此时需要将概率限定在0和1之间,所以线性模型不再适用。
我们期望的结果是输入一个x,比如之前提到的图片的数据集,返回的结果就是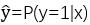
也就是求当输入图片的时候,判断这张图片是否是猫的概率。约定逻辑回归的两个参数,一个是w,一个是b,其中w也是一个n(x)维的向量,b代表实数,我们可以考虑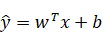
也就是x的线性组合,但是这样处理的话可能导致值超出0到1这个范围,所以此处用到了sigmoid函数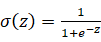
这样就能保证当数据极大时,概率接近1,数据极小时,概率接近0。有关sigmoid函数之前已经有过介绍,不再重复。所以此时的重点就是训练w和b的值,让这些参数能更好的拟合训练数据,以提高测试结果的成功率。 - 代价函数(Cost function)
当给定了数据集{(x(1),y(1)),…,(x(m),y(m))},我们期望的结果自然是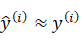
损失函数(Loss function)是一个需要自行进行定义的函数,主要是用来当运行到y时对输出值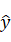 进行检测,我们可以使用半个平方差作为标准,不过这可能导致出现多个局部最优解,不利于梯度下降,所以在逻辑回归中我们采用
进行检测,我们可以使用半个平方差作为标准,不过这可能导致出现多个局部最优解,不利于梯度下降,所以在逻辑回归中我们采用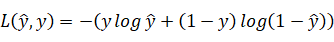 作为损失函数。损失函数的值自然是越小越好,所以解释一下为什么要用上述公式,因为当y=1时
作为损失函数。损失函数的值自然是越小越好,所以解释一下为什么要用上述公式,因为当y=1时 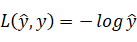 如果我们需要这个函数值特别小的话,我们就需要的值较大,又由于属于sigmoid函数,那么它的取值在0和1之前,所以此时自然是越接近1越好。当y=0时
如果我们需要这个函数值特别小的话,我们就需要的值较大,又由于属于sigmoid函数,那么它的取值在0和1之前,所以此时自然是越接近1越好。当y=0时 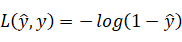 此时如果需要这个函数值变小,我们就需要的值越小,而它的取值在0和1之间,所以自然是越接近0越好。以上说明的是损失函数的情况,那么更早提到的代价函数是指的什么呢?它是用来检测优化组的整体运行情况,我们用J表示,则可以得到公式
此时如果需要这个函数值变小,我们就需要的值越小,而它的取值在0和1之间,所以自然是越接近0越好。以上说明的是损失函数的情况,那么更早提到的代价函数是指的什么呢?它是用来检测优化组的整体运行情况,我们用J表示,则可以得到公式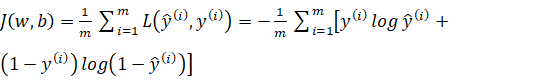
- 梯度下降(Gradient Descent)
在前面提到的损失函数J是一个凸函数(convex function),也就是说他具有局部最优解,注意,此处说的凸函数与我国数学教学中使用的凸函数相反,也就是说在国内应该绝大部分教的是凹函数。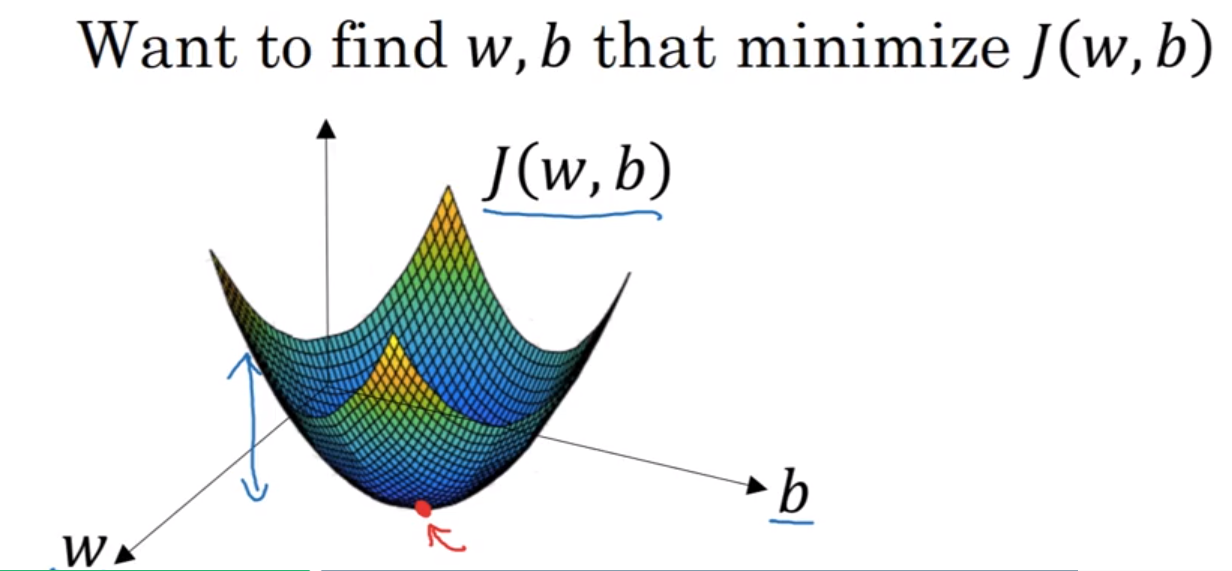
之所以选择一个凸函数,这是因为非凸函数可能有多个局部最优值。梯度下降的目的就是为了能到达到或者接近那个最优解。那么如何接近最优解呢,要接近最优解,我们就需要对参数w和b进行优化,采用的公式是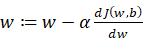 以及
以及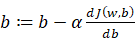 这里面的α就代表的学习率。
这里面的α就代表的学习率。 - 逻辑回归梯度下降

此处的da/dz实际上就是对sigmoid函数进行了求导,sigmoid函数是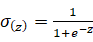 求导之后就成了
求导之后就成了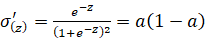 此处的a就代表了原来的sigmoid函数。
此处的a就代表了原来的sigmoid函数。
更多的补充说明:
Python广播机制